百度ERNIE2.0强势发布 (百度二年级语文上册)

17篇论文 详解图的机器学习趋势 (论文篇数是什么)

2022 十大领域!百度研究院发布 年十大科技趋势 涉及三大层面 (2022十大网络用语)

为桨 扬帆起航! 百度研究院发布2022年十大科技趋势!以AI为灯 (扬帆起航,为国争光什么意思)

光启慧语发布光语医疗大模型 联合上海中山医院探索智慧医疗新模式 (深圳光启智慧科技有限公司)

10倍GPT

巨量模型时代 打造全球最大中文语言模型 2457亿 浪潮不做旁观者 (巨量时代(深圳)科技有限公司)

2012年至今 细数深度学习领域这些年取得的经典成果 (2012年至2024年多少年)

数字人 支持NVIDIA 终端AI助手 悟道 GTX单卡机运行百亿大模型 首次落地 全球最大智能模型 (数字人ecdh)

TensorFlow最出色的30个机器学习数据集 (tensorflow)

思必驰俞凯 端到端与半监督语音识别的技术进展 (思必驰俞凯个人简介)

Vision平台 李飞飞发文发布谷歌云AutoML 订制化的企业级机器学习模型不再是难题 (vision pro 2)

这家企业走在了前面 预训练大模型产业落地的爆发前夜 (这家企业走在人生路上)

零一万物大模型Yi (零一万物大模型)

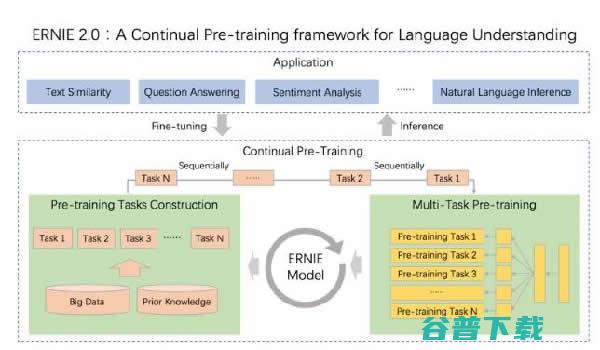
和 XLNet! ERNIE 百度开源自然语言理解模型 NLP 个 BERT 2.0 任务中碾压 16

12 NLP ChatGPT 还有 之后 个待解决命题 哈工大张民

现在和未来 语言模型的过去 Lab AI 总监李航 字节跳动 (现在和未来语录)

数据存储难 希捷HAMR技术4年让硬盘单盘容量翻倍! (数据 存储)


产品包括:汽车电瓶,汽车配件,汽车音响。公司的研发人员在吸收世界先进技术的基础上将科学技术知识应用的实际设计中,生产出了极具竞争力的产品。公司秉承顾客至上,锐意进取的经营理念,坚持客户第一的原则为广大客户提供优质的服务。在经济全球化的今天,将不断提升自我,打造完美诚信企业。 公司始终坚持科技领先,

展锋_新浪博客,展锋,展锋:临界点下收破,不翻多就观望!,展锋:临界点收破,调整开始?还是虚晃一枪?,展锋:临界点3126.17,得失非常关键!,展锋:临界点要盯牢,新高机会还有!,展锋:继续弱势回落,临界点得失关键!,展锋:突破回落伤人气,还会继续上涨吗?,展锋:突破3066.94翻多,持续性还需观察!,展锋:2993.14得失关键,耐心等待再图谋!,展锋:317家个股跌停,护盘的意义何在?,展锋:“国九条”利多来袭,大盘会拉长阳吗?

4399战斗机小游戏大全收录了国内外战斗机类小游戏、双人战斗机小游戏、战斗机无敌版小游戏、战斗机小游戏下载。好玩就拉朋友们一起来玩吧!

企鲸客定制开发的scrm企业微信是新一代CRM,企业微信scrm源码开发,有企业微信scrm系统软件,私域流量,企微scrm管理系统,企业微信客户管理系统,销售管理系统等工具,可以实现客户精细化管理和运营,会话存档,渠道活码,群营销,拓客裂变,话术管理,二次营销,用户画像和sop打造.

山东开拓金属制品有限公司

首页,青藤绿色建筑(广东)有限公司

心情日记|心情随笔|灵感记录|点滴记忆|星燎博客

宏远公司成功研发“金潮”品牌尼龙管件、球阀系列,POM管件、三角阀、水嘴、浮球,以及混水阀、家用净水器、纳米塑钢水龙头等系列产品,拥有独立的知识产权。

米拓建站专注于为中小企业提供高质量的建站服务,海量模板请登录www.mituo.cn,本站为律师事务所响应式网站模板演示站

传奇sf发布网(传奇私服发布网)提供的新开传奇sf是用户首选的传奇私服网,专注于发布刚开今天新开传奇网站信息,海量传奇私服网站任你浏览.

庆云明德塑业有限公司生产经营塑料桶、塑料托盘、塑料储罐的企业,主要产品有:25升塑料桶,50升塑料桶,200升塑料桶,吨桶,200升化工桶,1吨塑料桶,5吨塑料桶,10吨塑料桶,20吨塑料桶,卧式储罐等,公司秉承“诚信至上,锐意创新”的经营理念,为广大客户提供优良的产品及服务。

嘉乐嘉兴网络公司【手机:133-9573-1155】专注嘉兴网站建设,嘉兴微信小程序开发制作的嘉兴网络公司,主要业务有:嘉兴网站建设、小程序商城开发、嘉兴网站设计,嘉兴网页设计制作,嘉兴网站优化推广,嘉兴微信小程序开发等。

